Datawhale AI夏令营第四期魔搭-AIGC文生图方向Task1笔记
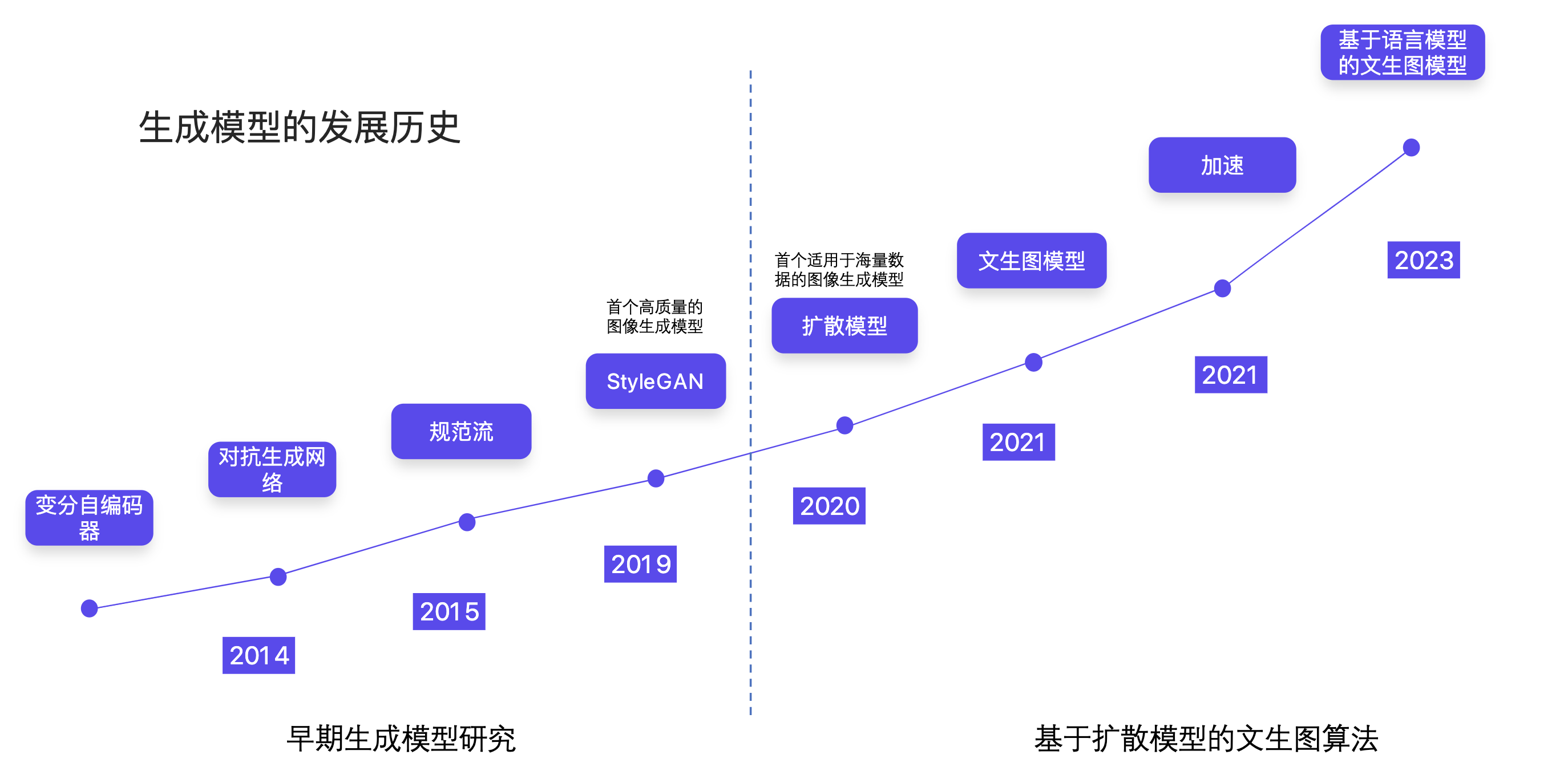
发展阶段 发展介绍
早期探索 (20世纪60年代-20世纪90年代)文生图的概念最早出现于计算机视觉和图像处理的早期研究中。早期的图像生成技术主要依赖于规则和模板匹配,通过预定义的规则将文本转换为简单的图形。然而,由于计算能力和算法的限制,这一阶段的技术能力非常有限,生成的图像质量较低,应用场景也非常有限。
基于统计模型的方法 (2000年代)进入2000年代,随着统计模型和机器学习技术的发展,文生图技术开始得到更多关注。研究者们开始利用概率图模型和统计语言模型来生成图像。尽管这一阶段的技术在生成图像的多样性和质量上有了一定提升,但由于模型的复杂性和计算资源的限制,生成的图像仍然较为粗糙,不够逼真。
深度学习的崛起 (2010年代)2010年代是文生图技术发展的一个重要转折点。随着深度学习,尤其是卷积神经网络 (CNN)和生成对抗网络 (GAN)的发展,文生图技术取得了突破性进展。2014年,Goodfellow等人提出的GAN模型通过生成器和判别器的对抗训练,极大地提升了图像生成的质量。随后,各类变种GAN模型被提出,如DCGAN、Pix2Pix等,使得文生图技术在生成逼真图像方面达到了前所未有的高度。
大规模预训练模型 (2020年代)进入2020年代,大规模预训练模型如OpenAI的CLIP、DALL-E以及Stable Diffusion等的出现,标志着文生图技术进入了一个新的时代。CLIP通过大规模的文本和图像配对数据训练,能够理解和生成高度一致的文本和图像;DALL-E和Stable Diffusion进一步提升了生成图像的创意和细节表现能力,使得通过简单的文本描述生成高质量、复杂图像成为可能。这些技术的应用范围从艺术创作、广告设计到辅助医疗诊断,展现了广泛的商业价值和社会影响力。
概念解析:
代码详解 环境安装:引入必要库(install后除了’-‘ + 字母外(表示安装选项)的名称均为库) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 !pip install simple-aesthetics-predictor !pip install -v -e data-juicer !pip uninstall pytorch-lightning -y !pip install peft lightning pandas torchvision !pip install -e DiffSynth-Studio
效果预览
下载数据集 1 2 3 4 5 6 7 8 9 10 from modelscope.msdatasets import MsDatasetds = MsDataset.load( 'AI-ModelScope/lowres_anime' , subset_name='default' , split='train' , cache_dir="/mnt/workspace/kolors/data" )
无输出
加载数据集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import json, osfrom data_juicer.utils.mm_utils import SpecialTokensfrom tqdm import tqdmos.makedirs("./data/lora_dataset/train" , exist_ok=True ) os.makedirs("./data/data-juicer/input" , exist_ok=True ) with open ("./data/data-juicer/input/metadata.jsonl" , "w" ) as f: for data_id, data in enumerate (tqdm(ds)): image = data["image" ].convert("RGB" ) image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id} .jpg" ) metadata = {"text" : "二次元" , "image" : [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id} .jpg" ]} f.write(json.dumps(metadata)) f.write("\n" )
效果预览
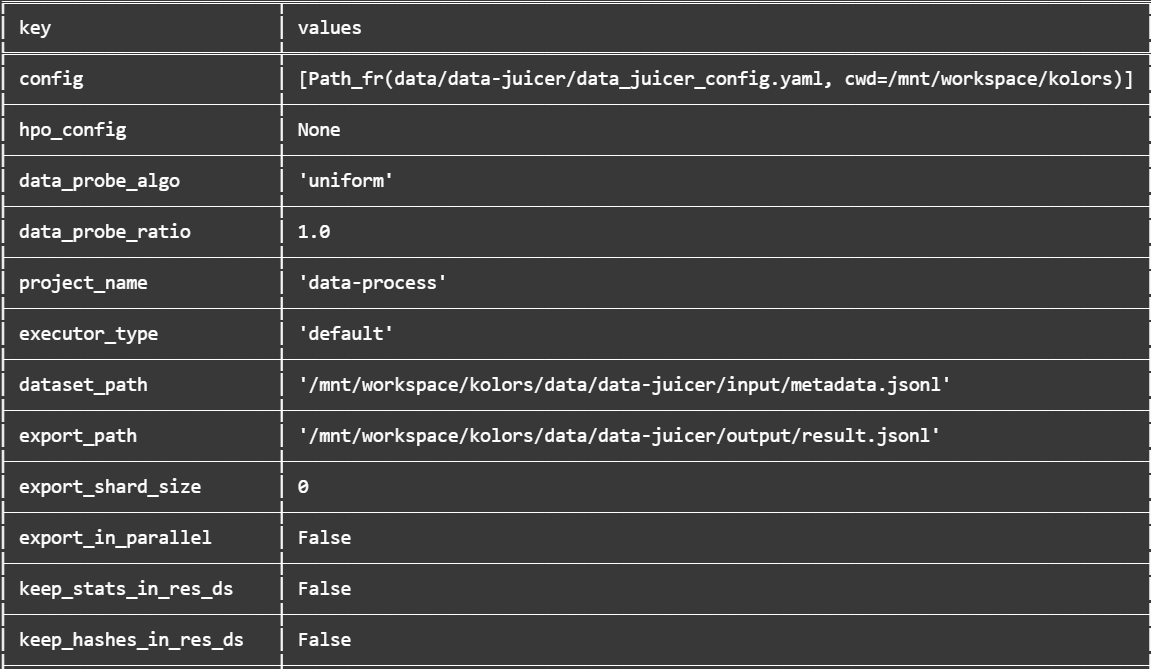
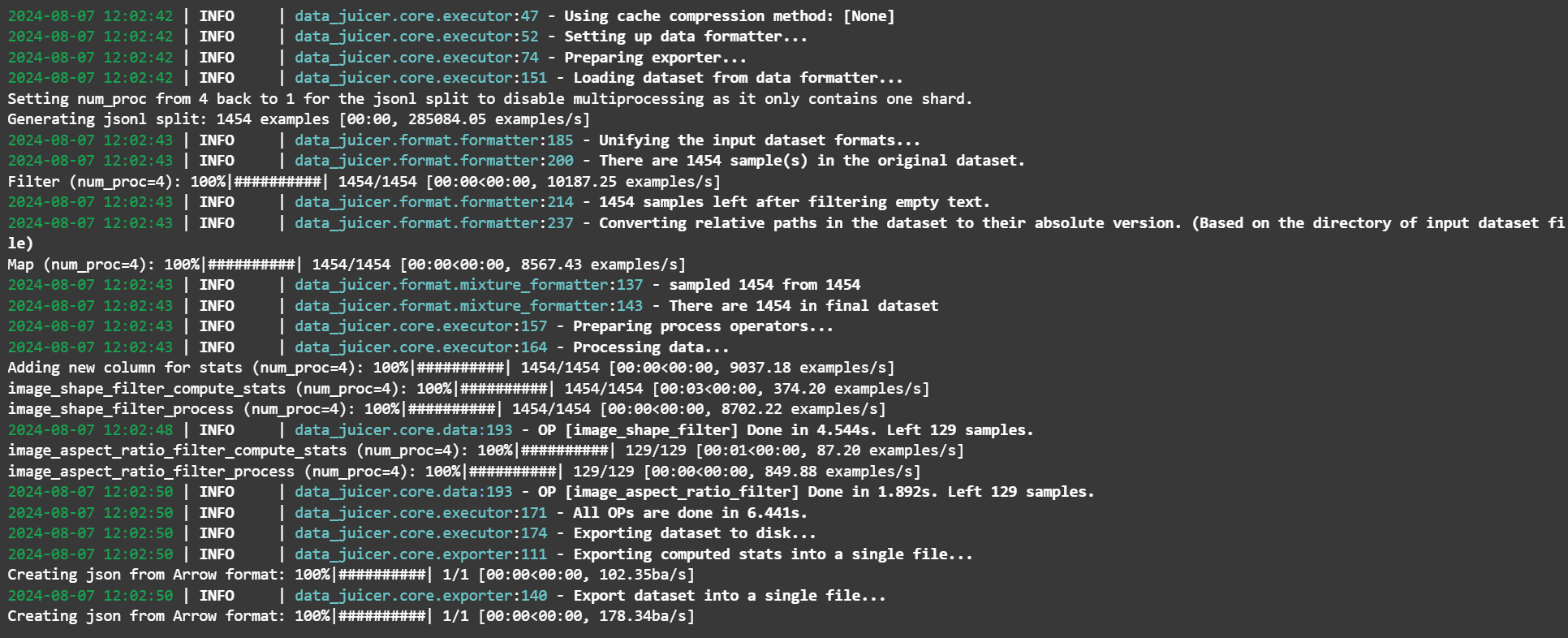
处理数据集,保存数据处理结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 data_juicer_config = """ # global parameters 全局变量 project_name: 'data-process' dataset_path: './data/data-juicer/input/metadata.jsonl' # 数据集路径 np: 4 # 子进程数量,用于并行处理数据集 text_keys: 'text' # 文本字段的键,设置为text image_key: 'image' # 图像字段的键,设置为image # 上一个代码段中写入字典(metadata)中设置键 - 值 image_special_token: '<__dj__image>' # 图像特殊标记 export_path: './data/data-juicer/output/result.jsonl' # 导出的结果文件路径 # 处理计划 process: - image_shape_filter: # 处理图像尺寸 min_width: 1024 min_height: 1024 any_or_all: any - image_aspect_ratio_filter: # 处理图像长宽比 min_ratio: 0.5 max_ratio: 2.0 any_or_all: any """ with open ("data/data-juicer/data_juicer_config.yaml" , "w" ) as file: file.write(data_juicer_config.strip()) !dj-process --config data/data-juicer/data_juicer_config.yaml
效果预览
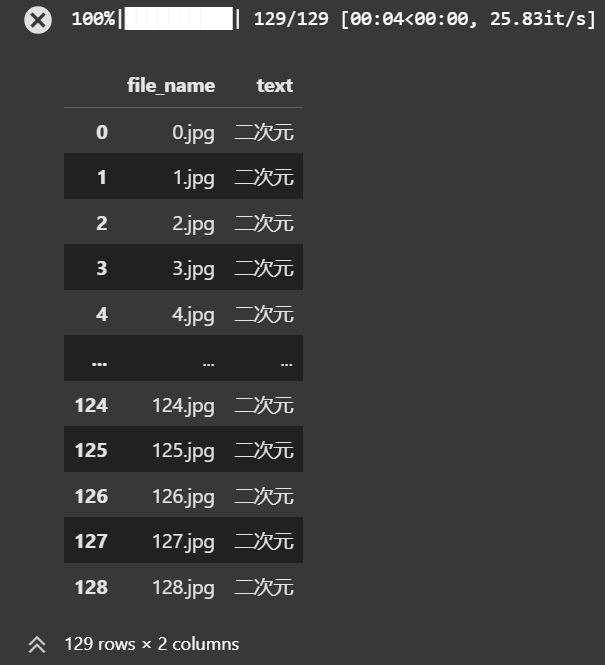
加载数据集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import pandas as pdimport os, jsonfrom PIL import Imagefrom tqdm import tqdmtexts, file_names = [], [] os.makedirs("./data/lora_dataset_processed/train" , exist_ok=True ) with open ("./data/data-juicer/output/result.jsonl" , "r" ) as file: for data_id, data in enumerate (tqdm(file.readlines())): data = json.loads(data) text = data["text" ] texts.append(text) image = Image.open (data["image" ][0 ]) image_path = f"./data/lora_dataset_processed/train/{data_id} .jpg" image.save(image_path) file_names.append(f"{data_id} .jpg" ) data_frame = pd.DataFrame() data_frame["file_name" ] = file_names data_frame["text" ] = texts data_frame.to_csv("./data/lora_dataset_processed/train/metadata.csv" , index=False , encoding="utf-8-sig" ) data_frame
效果预览
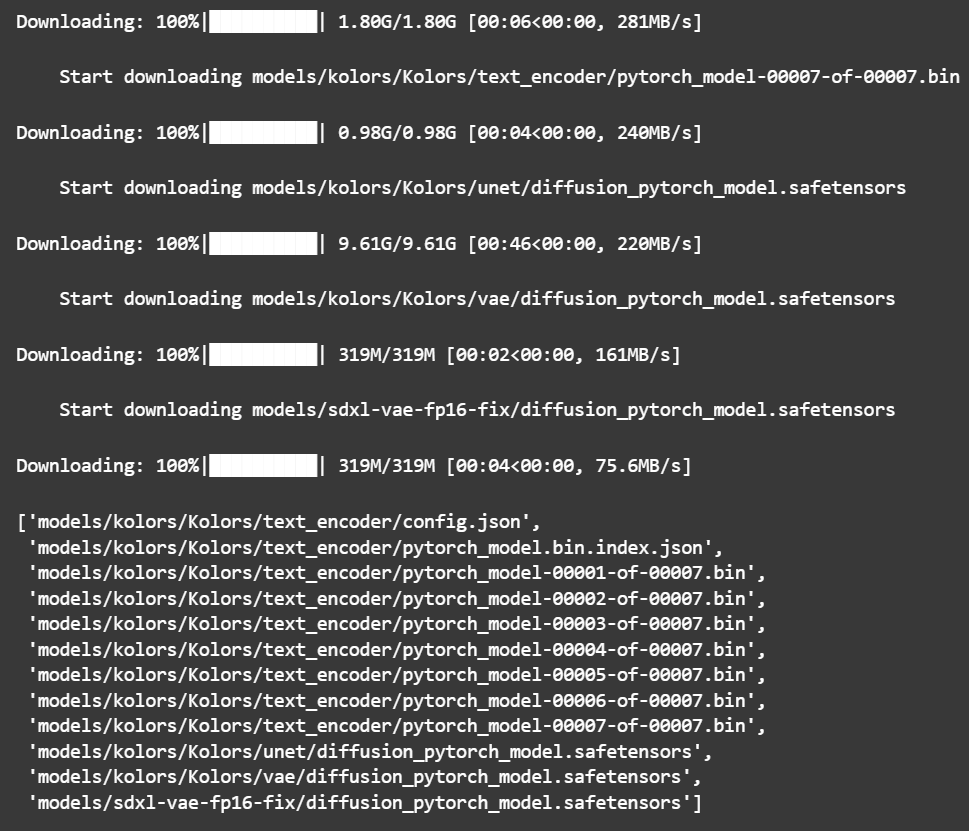
下载模型 1 2 3 4 from diffsynth import download_modelsdownload_models(["Kolors" , "SDXL-vae-fp16-fix" ])
效果预览
.
查看训练脚本的输入参数 1 !python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py -h
效果预览
lora微调
概念解析:
LoRA(Low-Rank Adaptation)是一种高效的模型微调方法,旨在减少在大规模预训练模型上进行微调时的计算和存储开销。LoRA 的核心思想是通过在模型的特定层中引入低秩矩阵,来减少模型参数的调整范围,从而实现更高效的微调。
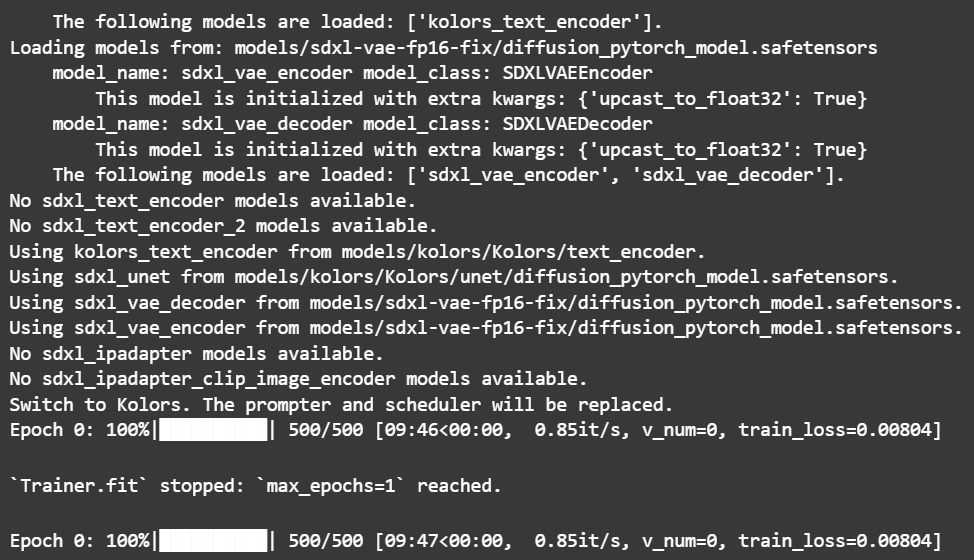
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import oscmd = """ python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \ # 指定要运行的 Python 脚本 --pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \ --pretrained_text_encoder_path models/kolors/Kolors/text_encoder \ --pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \ # 指定预训练模型的路径 --lora_rank 16 \ # 设置 LoRA 的秩为 16 --lora_alpha 4.0 \ # 设置 LoRA 的 alpha 参数为 4.0 --dataset_path data/lora_dataset_processed \ # 指定数据集的路径 --output_path ./models \ # 指定训练模型的输出路径 --max_epochs 1 \ # 设置最大训练轮数为 1 --center_crop \ # 启用中心裁剪 --use_gradient_checkpointing \ # 启用梯度检查点 --precision "16-mixed" # 设置训练的数值精度为混合 16 位精度 """ .strip()os.system(cmd)
效果预览
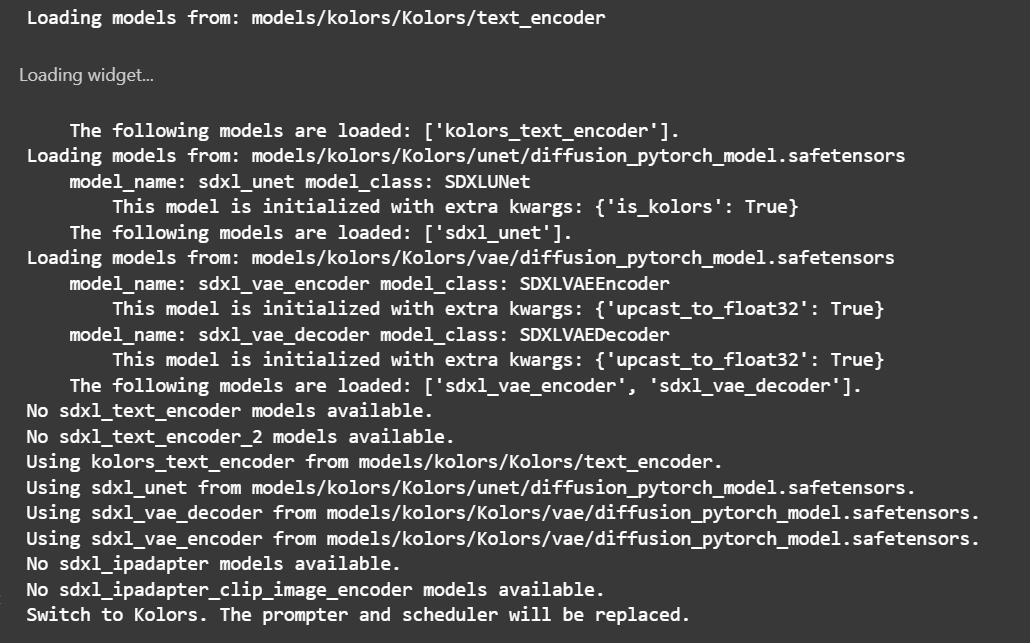
加载微调好的模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from diffsynth import ModelManager, SDXLImagePipelinefrom peft import LoraConfig, inject_adapter_in_modelimport torchdef load_lora (model, lora_rank, lora_alpha, lora_path ): lora_config = LoraConfig( r=lora_rank, lora_alpha=lora_alpha, init_lora_weights="gaussian" , target_modules=["to_q" , "to_k" , "to_v" , "to_out" ], ) model = inject_adapter_in_model(lora_config, model) state_dict = torch.load(lora_path, map_location="cpu" ) model.load_state_dict(state_dict, strict=False ) return model model_manager = ModelManager(torch_dtype=torch.float16, device="cuda" , file_path_list=[ "models/kolors/Kolors/text_encoder" , "models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors" , "models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors" ]) pipe = SDXLImagePipeline.from_model_manager(model_manager) pipe.unet = load_lora( pipe.unet, lora_rank=16 , lora_alpha=2.0 , lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt" )
效果预览
图片生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 torch.manual_seed(0 ) image = pipe( prompt="二次元,一个紫色短发小女孩,在家中沙发上坐着,双手托着腮,很无聊,全身,粉色连衣裙" , negative_prompt="丑陋、变形、嘈杂、模糊、低对比度" , cfg_scale=4 , num_inference_steps=50 , height=1024 , width=1024 , ) image.save("1.jpg" )
成片展示:小猫咪和青年的同居生活
正向提示词:卡通,一个可爱的灰色小猫咪,在一个圆形睡垫睡着,头埋在胸前,很悠闲,全身,处在一个房间内,毛发柔顺
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个毛发柔顺的灰色小猫咪躺在圆形睡垫上,抬头望向门口,露出惊喜的神情
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个穿着休闲白衬衫和牛仔裤的青年打开门,低头看向屋内,一只毛发柔顺的灰色小猫咪,睡在睡垫
负面提示词:丑陋、变形、嘈杂、模糊、低对比度,色情擦边
正向提示词:卡通,一个毛发柔顺的灰色小猫咪,从屋内跑向门口,开心
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个穿着休闲白衬衫和牛仔裤的青年蹲在地上,给一个毛发柔顺的灰色小猫咪喂食,小猫咪贴近青年的手吃食物
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个穿着休闲白衬衫和牛仔裤的青年坐在沙发上,青年用手抚摸怀中的一个毛发柔顺的灰色小猫咪,面前有一台电视
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个穿着休闲白衬衫和牛仔裤的青年给一个灰色小猫咪洗澡,青年帅气,白净,猫咪可爱,毛发柔顺
负面提示词:丑陋、变形、嘈杂、模糊、低对比度
正向提示词:卡通,一个穿着休闲白衬衫和牛仔裤的青年抱着一个灰色小猫咪睡在床上,年帅气,白净,猫咪可爱,毛发柔顺
负面提示词:丑陋、变形、嘈杂、模糊、低对比度