
OO_第三单元
测试策略
黑箱测试
- 别称:功能测试、封闭盒测试或基于规格说明的测试
- 定义:测试人员不需要了解被测试对象的内部逻辑结构、内部特性或源代码,仅关注测试对象的输入和输出,检查测试对象是否按照需求规格说明书的规定正常工作。
- 理解:进行黑箱测试仅得到输入与输出,设计测试案例时,需要保证覆盖符合规格说明书的所有范围(包含功能、边界等),以及保证输出对应相应的输入要求。
白箱测试
- 别称:结构测试、透明盒测试或基于代码的测试
定义:测试人员需要了解被测试对象的内部逻辑结构、内部特性和源代码,基于这些内部信息来设计测试用例,以检查测试对象的内部结构和代码是否按预期工作
理解:进行白箱测试可得到输入与输出以及测试对象的源代码,需要了解其内部逻辑结构以及内部特性,故除了进行黑箱测试的相同测试外,还可进行依据上述信息针对性地测试,测试其逻辑结构是否正确的
单元测试
- 内容:针对软件的最小可测试单元(通常是代码中的一个模块、方法或类)进行测试
- 特性:每个单元测试间自动,独立运行,可设定条件进行针对测试
- 编写方法:
- 完成测试用例的编写,即数据生成
- 本课程中使用的测试框架为
Junit,对不同单元根据JML规格完成断言assert验证
- 要求:
- 设计可靠全面的测试样例保证足够的测试覆盖率
- 当代码发生更改或需求发生变化,需维护测试
功能测试
- 内容:
- 功能测试通常涵盖软件的各个模块和功能点
- 测试人员需要验证系统的功能是否符合设计文档和用户需求规格说明书中定义的要求。
- 要求:
- 可在软件开发的各个阶段进行,但通常在系统测试阶段进行集中测试。
- 如果测试用例全部通过,则说明系统的功能基本满足用户需求;如果存在测试用例失败的情况,则需要分析失败的原因,并修复相应的缺陷。
- 测试方法:(根据名称可推断其测试方法)
- 黑箱测试
- 场景测试
- 边界测试
- 等价类测试
集成测试
- 内容:确保软件的各个部分在组合后能够正常工作,并且它们之间的接口和交互没有问题。通过集成测试,可以验证系统的整体功能是否满足设计要求,并发现模块之间的接口错误、数据传递错误等问题。
- 要求:
- 集成测试通常在单元测试之后进行。
- 测试方法:自顶向下集成、自底向上集成、大爆炸集成和增量集成
- 测试内容:模块之间的接口测试、全局数据结构测试、资源访问冲突测试、错误处理测试
压力测试
- 内容:压力测试是模拟系统在高负载或异常情况下的表现,以评估其性能、稳定性和可靠性。
- 作用:
- 发现潜在问题:在压力测试过程中,系统可能暴露出在正常操作条件下不易发现的问题,如内存泄漏、资源竞争、性能瓶颈等。
- 评估系统性能:通过模拟高负载场景,可以评估系统在不同压力下的响应时间、吞吐量、错误率等性能指标。
- 优化系统配置:根据压力测试的结果,可以对系统配置进行优化,如调整数据库连接池大小、增加缓存容量、优化代码逻辑等,以提高系统性能。
- 制定扩容计划:通过模拟高并发场景,可以预测系统在未来可能面临的负载压力,从而制定合理的扩容计划。
- 测试方法:负载测试,容量测试,故障注入测试,资源限制测试
- 要求:
- 确保测试环境与生产环境尽可能相似,以便更准确地模拟实际场景。
- 使用真实数据进行测试,以确保测试结果的准确性。
回归测试
- 内容:回归测试指当软件或应用发生变更(如修复缺陷、增加新功能或修改现有功能)时,重新运行之前的测试用例,以确认新代码没有引入新的错误,并且之前的功能仍然按预期工作。
- 目的:确保系统的稳定性和可靠性,防止因代码更改而导致的新问题或旧问题的回归。
- 测试方法:
- 完全重复测试:重新执行所有在前期测试阶段建立的测试用例,以确认问题修改的正确性和修改的扩散局部影响性。这种方法适用于系统变更较小,且测试资源充足的情况。
- 选择性重复测试:根据变更的特性和风险,有选择地重新执行部分在前期测试阶段建立的测试用例。这种方法可以节省测试资源,但需要对测试用例的选择有足够的依据和判断力。
- 要求:
- 测试数据:确保用于回归测试的数据与之前的测试数据保持一致,以便准确评估变更对系统的影响。
- 测试环境:确保回归测试的环境与之前的测试环境一致,以排除环境因素对测试结果的影响。
- 自动化工具:使用自动化测试工具进行回归测试可以大大提高测试效率,减少人为错误。
- 持续监控:在回归测试过程中,需要持续监控系统的性能和稳定性,及时发现并解决问题。
测试工具
未使用测试工具
数据构造策略
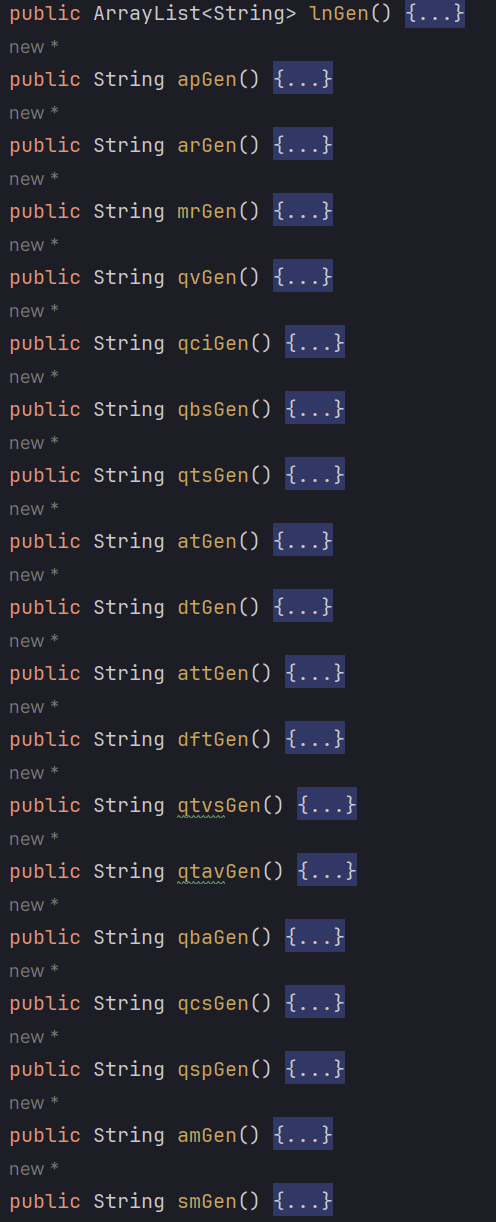
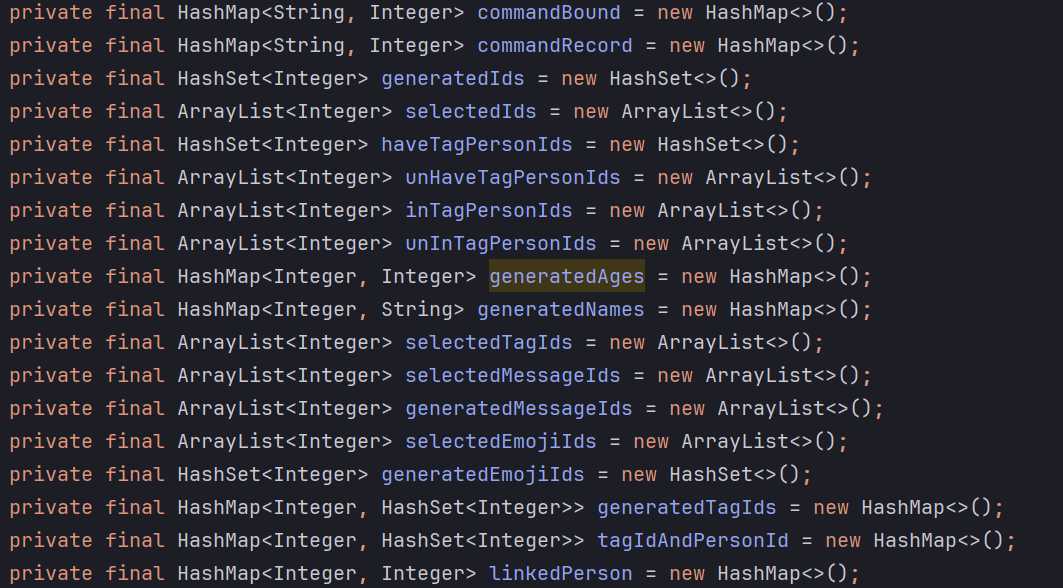
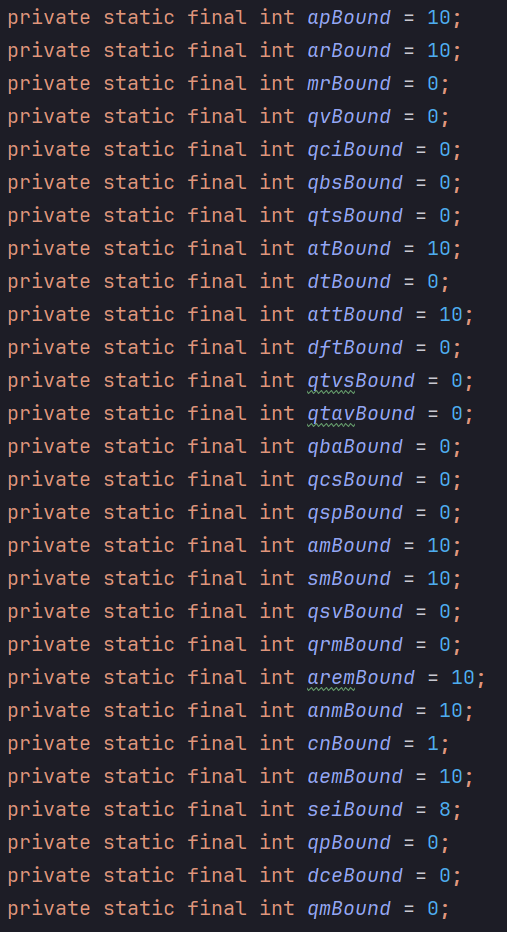
为每一种指令构造其生成函数,
lnGen(), apGen()等为相关指令维护其共享的容器,生成指令时,可从容器中随机选择对象,
generatedIds,selectedIds等为每一种指令设置边界值,每一轮次需保证每一种指令出现次数达到边界值,可保证每条指令出现的频率
可通过设置如下变量设置正确指令(不抛出异常)的概率,通过从指定容器中随机抽取对象,从而保证符合函数的处理要求
1
private static final int correctCommand = 10;
架构分析
UML类图
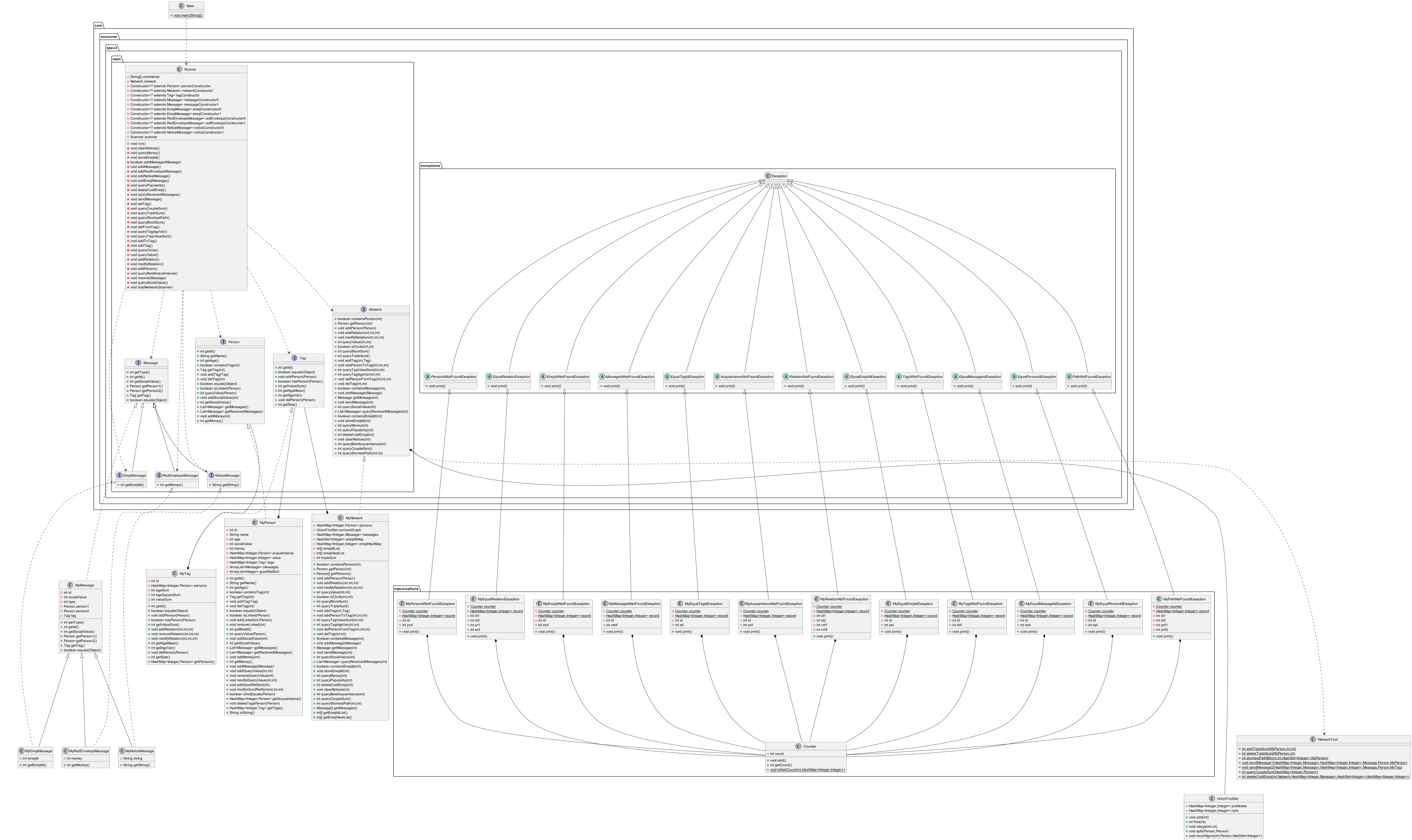
图模型构建策略
并查集
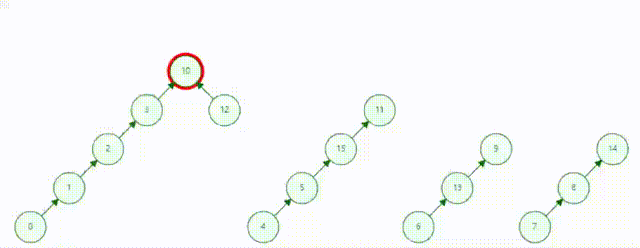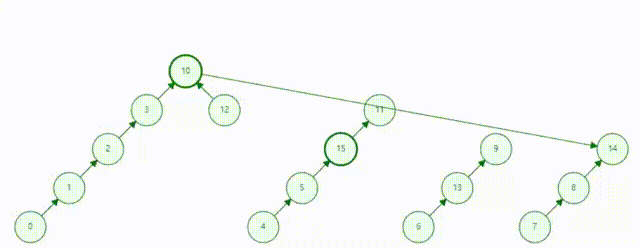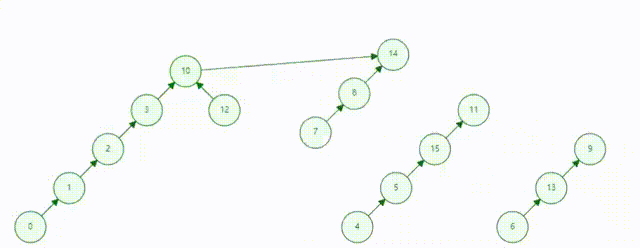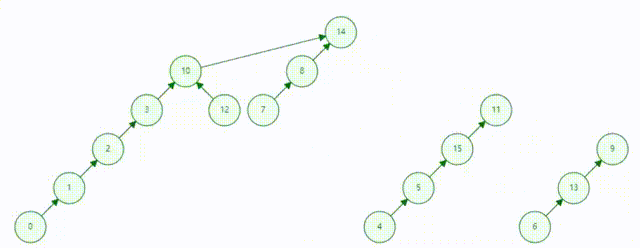
描述:并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并、查)
作用:并查集的主要作用是求连通分支数
主要构成:
2
private final HashMap<Integer, Integer> rank;前者(
preNodes)记录前驱结点,但经过路径压缩后,同一个连通分支内的所有结点的前驱结点均设置为代表结点(前驱结点为自身),便于判断两个结点是否位于同一个连通分支内。后者(
rank)记录结点的深度(秩),默认根节点(代表结点)的深度为1,用于按秩合并,为降低两个树(以代表元为根结点)合并后得到的树的高度,需要将高度(秩)较低的树的根结点指向高度(秩)较高的树的根结点,并要完成路径压缩。
1 | //添加元素 |
并查集动态表示
维护策略
MyNetwork类
1 | private final HashMap<Integer, Person> persons; |
tripleSum维护this对象中的容器persons内三个Person符合互相满足isLinked状态的个数,需要在MyNetwork调用add_relation,modify_relation时进行维护。
MyPerson类
1 | private final ArrayList<Integer> goodRelSort; |
上述容器维护与this对象之间的value递减的MyPerson的id序列,相同value的需维护id较小的在前,需要在MyNetwork调用add_relation,modify_relation时进行维护。
MyTag类
1 | private final HashMap<Integer, Person> persons; |
persons储存this对象的所有PersonageSum需要维护persons中的所有Person对象的年龄和ageSquareSum需要维护persons中的所有Person对象的年龄的平方和valueSum需要维护persons中的所有Person对象与this对象之间的value和
ageSum和ageSquareSum仅需要在addPerson和delPerson时,进行相应的维护
valueSum 需要在addPerson和delPerson时,根据条件判断是否要更改valueSum,同时在MyNetwork调用add_relation,modify_relation时进行维护(根据实际更新或者删除对象之间的value)
性能问题及其修复情况
性能问题
在第二次作业中,未对MyTag类的ValueSum进行维护,单纯根据JML进行双循环遍历,复杂度为$𝑂(𝑛^2)$,导致在往特定的MyTag中加入过多Person后,反复查询其ValueSum,导致超时。
修复情况
故将ValueSum设置为MyTag的私有属性,通过在addRelation,modifyRelation遍历已有的所有MyTag,依据其内的persons对ValueSum进行维护;除此之外,当在MyTag中删减person时,也需维护ValueSum,从而在查询MyTag的ValueSum时,可直接返回MyTag的属性ValueSum即可,复杂度$O(1)$。
规格与实现分离
理解
规格定义方法或系统需要满足的要求,包含限制规则,前置条件,后置条件,副作用范围限定等,但不需要关注实现的方法与过程。
好处
- 降低耦合度:当规格和实现分离时,不同的实现可以更容易地替换或添加,而无需修改其他部分的代码。这种低耦合性使得系统更加灵活,能够适应不断变化的需求。此外,它还有助于实现代码重用,因为相同的规格可以被不同的实现所共享。
- 提高可测试性:规格为测试人员提供了明确的测试依据。他们可以创建测试用例来验证系统是否按照规格的要求运行,而无需关心底层的实现细节。此外,由于规格和实现是分开的,测试人员可以更容易地模拟或替换某些难以测试的实现部分,以便进行更全面的测试。
- 支持并发开发:在大型项目中,规格与实现分离有助于实现并发开发。不同的开发团队可以分别负责不同的实现部分,而无需担心相互之间的依赖关系。他们只需要确保自己的实现遵循了共同的规格即可。
- 促进文档化:规格通常作为系统的文档存在,它描述了系统的功能和行为,但不涉及具体的实现细节。这使得非技术人员(如项目经理、测试人员等)能够更容易地理解系统的需求和行为,从而更好地与开发人员协作。
- 简化维护过程:当系统需要更新或修复时,开发人员只需要关注实现部分,而无需修改规格。这使得维护过程更加简单和高效。此外,由于规格和实现是分开的,开发人员可以更容易地定位问题所在并进行修复。
Junit测试
对验证代码实现与规格的一致性的作用
样例
- 在编写
JUnit测试用例时,由于需要依据规格明确代码的预期行为和输出。故可通过测试用例,验证代码满足与规格的一致性,并且在边界条件和异常情况下是否能够正确处理。 JUnit允许独立编写测试,可针对代码的每个部分或功能编写单独的测试用例,从而更精确地验证代码实现与规格的一致性。
测试
JUnit提供一套断言方法(如assertTrue(),assertFalse(),assertNull(),assertNotNull()等),故能够通过断言方法验证代码的行为是否符合预期的规格。如果实际输出与预期不符,测试将失败,并给出相应的错误信息,帮助开发者快速定位问题。
改进和建议
- 生成测试样例
- 推荐先构造数据生成器,可通过数据生成器调节测试样例的规模,尽可能覆盖功能,边界情况
- 使用参数化测试,使用不同的输入值和预期输出值来运行相同的测试用例
- 编写测试代码
- 需要完全按照规格的要求,一一进行断言测试,保证测试的可靠性与覆盖率
- 添加异常捕获,确保抛出异常时,可判断异常是否符合规格要求,如符合则进行捕获,反之抛出异常,终止测试
学习体会
- 刚开始接触
JML,需要充分阅读并理解相关文档,相当于掌握一门新的”语言“,在实际完成作业时,因为指导书中指出需要根据JML理解本次作业内容,没有给予细致的描述,要充分阅读每一个方法的JML规格,主动联系起来才能理解作业目标。但是在实际编写代码时,只要关注并符合每一个方法的JML规格即可,通过设计合理的架构保证符合规格,降低复杂度(时间或空间,依情况而定) - 本单元对图的应用较多,需要重新学习关于图的算法,并学习到新的树型的数据结构——并查集,深刻理解了不同的数据结构能极大降低算法的复杂度,同时对同一个数据结构的特定优化也能降低复杂度
- 本单元独自完成评测机的搭建,同时上传到
github进行分享,收到使用者的赞扬,在开发过程中,需要保证迭代的连续性,并尽可能便于使用者理解与使用。 - 进行
Junit测试时,使用上述评测机的数据生成器产生测试样例,能自行调节测试样例的规模与指令比例,极大提高覆盖率。编写方法的测试代码时,需注重是否验证pure特性,并关注通过方法得到的容器属性是深拷贝还是浅拷贝,若是浅拷贝则需要new一个相同的对象便于进行方法执行前后的比对。 - 整体而言,本单元的学习相较于前两个单元是轻松的,并能借此机会开发搭建评测机,除了不考虑由于
JML导致的理解偏差以及其本身的不易读性,还是不错的




