
OS_Lab2
Thinking2.1
Thinking 2.1 请根据上述说明,回答问题:在编写的 C 程序中,指针变量中存储的地址被视为虚拟地址,还是物理地址?MIPS 汇编程序中 lw 和 sw 指令使用的地址被视为虚拟地址,还是物理地址?
answer
两者都是虚拟地址
Thinking2.2
Thinking 2.2 请思考下述两个问题:
- 从可重用性的角度,阐述用宏来实现链表的好处。
- 查看实验环境中的 /usr/include/sys/queue.h,了解其中单向链表与循环链表的实现,比较它们与本实验中使用的双向链表,分析三者在插入与删除操作上的性能差异。
- answer
- 类型灵活性:宏可以接受类型参数,可为不同的数据类型创建链表,而无需编写多个不同的链表实现。通过传递不同的类型给宏,为任何数据类型创建链表。
- 减少代码冗余:使用宏可以避免在多个地方重复编写相同的链表节点结构体定义(通过引用宏即可)。
- 易于维护:由于链表节点的定义是通过宏来实现的,因此需要修改链表节点的结构,只需要修改宏的定义即可,可以在整个代码中统一更新链表节点的结构。
- 跨项目重用:由于宏是在预处理阶段展开的,它们可以很容易地跨多个项目或库进行重用。
- answer
- 单向链表和循环链表:在进行遍历寻找目标结点时,若不保存当前结点和前一个结点,需要在找到目标结点后重新遍历得到前一个结点进行插入和删除操作。(包含一个数据元素和一个指向下一个结点的指针)
- 循环链表:在进行遍历寻找目标结点时,无需保存当前结点的前一个结点,只需要在找到目标结点直接进行进行插入和删除操作即可。(包含一个数据元素,一个指向下一个结点的指针和指向上一个结点的指针)
Thinking2.3
Thinking 2.3 请阅读 include/queue.h 以及 include/pmap.h, 将 Page_list 的结构梳理清楚,选择正确的展开结构。
A:
2
3
4
5
6
7
8
9
10
11
12
{
struct
{
struct
{
struct Page *le_next;
struct Page *le_prev;
} pp_link;
u_short pp_ref;
} *lh_first;
}B:
2
3
4
5
6
7
8
9
10
11
12
{
struct
{
struct
{
struct Page *le_next;
struct Page **le_prev;
} pp_link;
u_short pp_ref;
} lh_first;
}C:
2
3
4
5
6
7
8
9
10
11
12
{
struct
{
struct
{
struct Page *le_next;
struct Page **le_prev;
} pp_link;
u_short pp_ref;
} *lh_first;
}
answer
C
Thinking2.4
请思考下面两个问题:
- 请阅读上面有关 TLB 的描述,从虚拟内存和多进程操作系统的实现角度,阐述 ASID的必要性。
- 请阅读 MIPS 4Kc 文档《MIPS32® 4K™ Processor Core Family Software User’sManual》的 Section 3.3.1 与 Section 3.4,结合 ASID 段的位数,说明 4Kc 中可容纳不同的地址空间的最大数量。
- answer
上述表述中,ASID用于区分不同的地址空间。
由于TLB在多线程系统中,可能装入不同进程的页表项,而不同进程占用着不同的虚拟空间,由于同一虚拟地址在不同的地址空间中通常映射到不同的物理地址,故需要为每个进程分配其相应的ASID,在查找TLB表项时,除了确认VPN符合外,验证ASID符合方可决定该表项为该虚拟地址在该进程下的页表项。
没有ASID机制的情况下每次进程切换需要地址空间切换的时候都需要清空TLB。
answer
ASID6位,容纳64个不同进程。
Thinking 2.5
请回答下述三个问题:
- tlb_invalidate 和 tlb_out 的调用关系?
- 请用一句话概括 tlb_invalidate 的作用。
- 逐行解释 tlb_out 中的汇编代码。
- answer
tlb_invalidate调用tlb_out
- answer
tlb_invalidate通过调用tlb_out将虚拟地址为va以及进程码为asid在TLB的旧表项删除
- answer
1 | LEAF(tlb_out) |
Thinking 2.6
从下述三个问题中任选其一回答:
- 简单了解并叙述 X86 体系结构中的内存管理机制,比较 X86 和 MIPS 在内存管理上的区别。
- 简单了解并叙述 RISC-V 中的内存管理机制,比较 RISC-V 与 MIPS 在内存管理上的区别。
- 简单了解并叙述 LoongArch 中的内存管理机制,比较 LoongArch 与 MIPS 在内存管理上的区别。
X86 体系结构中的内存管理机制
- 内存地址由段基址和段内偏移地址组成
- 使用控制寄存器(CR0~CR3)控制和确定处理器的操作模式以及当前执行任务的特性
- 处理器通过段寄存器和地址段描述结构来访问特定的内存段。
- 段寄存器
- CS寄存器:程序指令段起始地址;
- DS寄存器:程序数据段起始地址;
- SS寄存器:栈起始地址;
- ES, FS, GS寄存器:额外段寄存器。
地址段描述结构
- 全局描述符表——GDT
- 局部描述符表——LDT
段页式地址映射
- 段映射机制,将逻辑地址映射到线性地址;
- 页映射机制,将线性地址映射到物理地址
比较 X86 和 MIPS 在内存管理上的区别
内存访问方式
- MIPS采用基于Load/Store的内存访问方式,即只能通过特定的加载和存储指令来访问内存。
- X86则提供了更直接的内存访问方式,可以通过指令直接操作内存地址。
TLB
当TLB不命中
- MIPS会触发特定的异常处理机制,由内核负责处理并更新TLB
- X86则通过硬件MMU直接进行地址转换并填充TLB
物理地址扩展
- MIPS不支持
- X86支持
段页式管理
- MIPS同时包含了段和段页式两种地址使用方式
- 在x86架构的保护模式下的内存管理中,分段是强制的,并不能关闭,而分页是可选的;
Thinking A.1
在现代的 64 位系统中,提供了 64 位的字长,但实际上不是 64 位页式存储系统。假设在 64 位系统中采用三级页表机制,页面大小 4KB。由于 64 位系统中字长为8B,且页目录也占用一页,因此页目录中有 512 个页目录项,因此每级页表都需要 9 位。因此在 64 位系统下,总共需要 3 × 9 + 12 = 39 位就可以实现三级页表机制,并不需要 64位。
现考虑上述 39 位的三级页式存储系统,虚拟地址空间为 512 GB,若三级页表的基地址为 PTbase,请计算:
- 三级页表页目录的基地址。
- 映射到页目录自身的页目录项(自映射)。
假设39位的[0:11],[12:20],[21:30],[31,39]依此表示页,三级页表,二级页表,一级页表
- 如果三级页表页目录的基地址表示一级页表的基地址:$ PT_{base} + (PT_base >> 12)*8$
- 如果三级页表页目录的基地址表示二级页表的基地址:其存储在一级页表的页表项中。
- $ PT_{base}[31:39] $表示映射到页目录自身的页目录项(一级页表)内的偏移量
- 映射到页目录自身的页目录项:$ PT_{base} + (PT_base >> 12)*8 + PT_{base}[31:39] $
难点分析
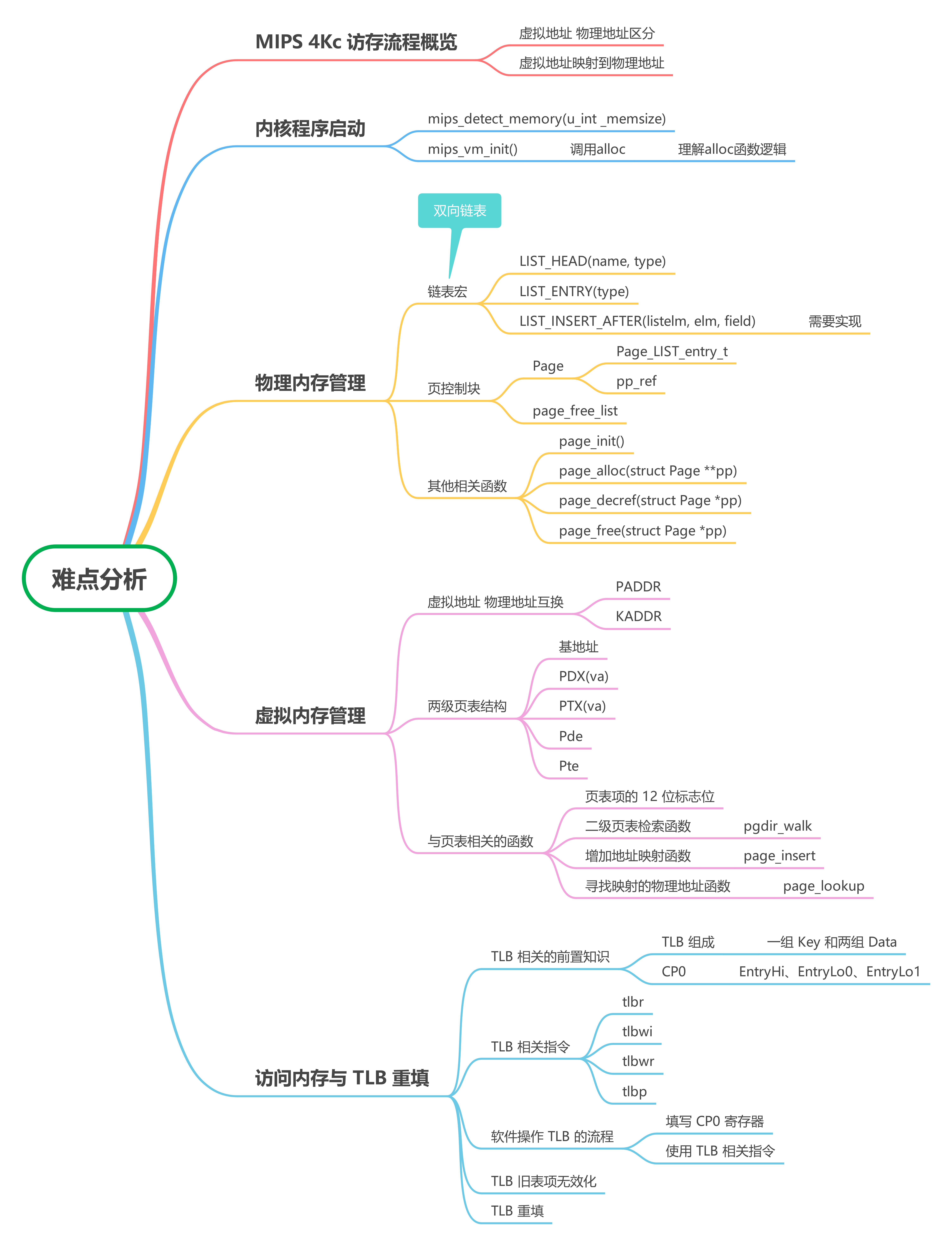
实验体会
- Lab2课下:
课下写了将近2周的时间,断断续续间,最终完成线上测验。
初步接触课下知识时,不能完全理解,推进进度期间不断反复复习理解看过的知识点,才逐步理解并掌握知识点。
课下习题帮助我更好地理解具体实现的过程,掌握文件间的联系以及函数的实现。
- lab2-exam:
注意:看清题目,题干要求标记次数pp_ref大于等于num(比较对象)
实现过程:遍历[va_lower_limit, va_upper_limit)间的虚拟地址,间隔为一个页面大小,参考page_lookup函数的实现,先利用page_walk查找va对应的二级页表项,保证存在页表项以及页表项有效(*pte & PTE_V != 0)的前提下,比较标记次数与num,进行计数。
- lab2_extra:
还是没有完成,呜呜呜呜!!!
课上花了不到一个小时的时间完成代码的初步实现,连测试样例都没过呢,回来之后在室友的指导下完成代码。
注意:
- 如何寻找伙伴:先转换为物理地址,再模
2*PAGE_SIZE,判断为伙伴的首项还是次项struct Page* page,page++则可以得到下一页面(此处为指针)- 充分使用链表宏的宏定义,完成链表操作
实现过程:
参考page_alloc和page_free函数的实现





